 |
Virtuelle Speicherverwaltung
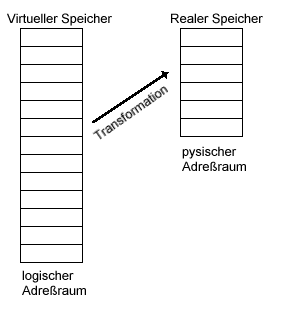
Man spricht von virtueller Speichertechnik, wenn der Speicheradreßraum, den
die Befehle des Prozessors referieren, getrennt ist von realen Adreßraum des Arbeitsspeichers, in dem sich das Programm bei der Abarbeitung befindet. Der Adreßraum, auf den sich die Programmbefehle beziehen, ist der logische Adreßraum. Der Adreßraum des realen Arbeitsspeichers ist der physische Adreßraum. --> Programme können unabhängig vom physischen Adreßraum geschrieben werden. Der logische Adreßraum beschreibt einen gedachten, nicht real vorhandenen Arbeitsspeicher, den man als virtuellen Speicher bezeichnet.
- logischer Adreßraum = virtueller Adreßraum
- logische Adresse = virtuelle Adresse
Normalerweise ist der logische Adreßraum größer als der physische
Adreßraum (meist sogar sehr viel größer). Der virtuelle Speicher
wird auf der Platte abgebildet.
Zur Ausführung muß ein Programm in den Arbeitsspeicher geladen werden.
Wegen der sequentiellen Abarbeitung werden innerhalb eines bestimmten Zeitintervalls
nicht alle Teile des Programms und analog auch nicht der gesamte Datenbereich
des Programms benötigt.
Es reicht also aus, nur die jeweils benötigten Programm- und Datenbereichs-Teile
(= "working set") im Arbeitsspeicher zu halten.
Die Programme und Daten werden in einzelne Teilabschnitte zerlegt, die dann nur
bei Bedarf (wenn sie von der CPU benötigt werden) in den Speicher geladen
werden.
- Programme und Datenbereiche sind in ihrer Länge nicht durch die reale
Größe des Arbeitsspeichers begrenzt
- Es können gleichzeitig mehrere Programme ausgeführt werden, deren
Gesamtlänge die Arbeitsspeicher-Größe überschreitet.
Zur Abarbeitung der einzelnem Befehle des Programms ist eine Transformation (Abbildung)
der logischen Adressen in physische Adressen erforderlich.
Die logische Adresse in den Befehlen bleibt auch nach dem Laden in den Arbeitsspeicher
unverändert erhalten. Die Transformation erfolgt erst bei der Befehlsausführung
--> dynamische Adreßtransformation (DAT).
Liegt eine Adresse in einem Programm- oder Datenabschnitt, der sich nicht im Arbeitsspeicher
befindet, wird der entsprechende Abschnitt nachgeladen.
Zur Realisierung der vituellen Speicherverwaltung muß eine Kombination aus
Hard- und Software eingesetzt werden. Das Nachladen der Programm- und Datenabschnitte
besorgt ein speziell konzipiertes Betriebssystem.
Grundvoraussetzung für die Realisierung ist die Fähigkeit der CPU, einen
laufenden Befehl zu unterbrechen (beim Nachladen) und nach erfolgtem Nachladen
den begonnenen Befehl erneut aufzusetzen und dann vollständig auszuführen.
Die virtuelle Speichertechnik ist für den Anwender vollkommen transparent.
Sowohl das Nachladen von Programm- und Datenabschnitten als auch die Adreßumsetzung
geschieht automatisch und braucht bei der Anwendungsprogrammierung nicht berücksichtigt
zu werden. Die Aufteilung des Speichers kann erfolgen als:
- Segmentierung
- Seitenadressierung (Paging)
Segmentierung
Der logische Adreßraum wird in Abschnitte variabler Größe gemäß
den logischen Einheiten des Programms (Unterprogramme, Datenbereiche, etc.) unterteilt.
Die Abschnitte nennt man Segmente. Die minimale/maximale Segmentgröße
hängt vom jeweiligen System ab (typisch: 256 Byte bis 64 KByte).
Die logische Adresse besteht aus 2 Teilen:
- Segment-Nummer (höchstwertiger Teil)
- Wortadresse (Offset, Displacement; niederwertiger Teil;
Adresse relativ zum Segmentanfang).
Für die in den Arbeitsspeicher geladenen Segmente ist in einer Segmenttabelle die jeweilige
reale Anfangsadresse des Segments festgehalten (Basisadresse des Segments).
Im Multiprogramming-Betrieb werden für die verschiedenen "Jobs" meist jeweils eigene
Tabellen bereitgestellt damit mit den Segment-Nummern verschiedener Jobs keine
Verwechslung möglich ist. Somit muß vor dem Segmenttabellenzugriff noch der Inhalt
eines jobspezifischen Segmenttabellenregisters zur Segmentnummer addiert werden.
Bei jedem Umschalten der Jobs (z. B. wegen "Verdrängen" einer Task am Zeitscheibenende)
muß deshalb auch das Segmenttabellenregister umgeladen werden!
Im allgemeinen enthält die Segmenttabelle auch Angaben über die Größe der Segmente
(Angabe der letzten physischen Adresse des Segments oder der Segmentgröße direkt).
Dadurch können fehlerhafte Zugriffe, die aus dem Segment herausführen, erkannt und
verhindert werden.
Weiterhin sind in der Segmenttabelle jedem Segment noch Zustands- und Zugriffsinformationen
zugeordnet (Erkennen nicht geladener Segmente, Verhinderung unberechtigter Zugriffe).
Das Segment ist die kleinste Austauscheinheit. Falls kein Speicherplatz zum Nachladen mehr
frei ist, muß ein vorhandenes, derzeit nicht benötigtes Segment entfernt werden
("demand segment swapping").
Probleme (gleichzeitig Nachteile der Segmentierung):
Speicherzersplitterung ("externe Fraktionierung"): Zwischen den im Arbeitsspeicher
befindlichen Segmenten sind nicht belegte Lücken vorhanden, die entstehen, wenn ein
Segment gegen ein kleineres Segment ausgetauscht bzw. entfernt wird.
Es kann Fälle geben, bei denen der verfügbare zusammenhängende Speicherraum nicht
groß genug ist, um ein neu zu ladendes Segment aufzunehmen, obwohl insgesamt genügend
freier Speicherplatz vorhanden ist.
Neuordnung der Arbeitsspeicher-Belegung durch das Betriebssystem wird
notwendig (Zusammenschieben der Segmente).
Umständlicher Austauschalgorithmus: Das zugehörige Systemprogramm belegt selbst
viel Speicherplatz, zusätzlicher Zeitbedarf für die Ausführung.
Seitenadressierung (Paging)
Logischer und physischer Adreßraum werden in Abschnitte gleicher Länge
eingeteilt, die man Seiten (Pages) nennt (typische Seitengrößen: 0,5 KByte ... 4 KByte).
Eine Seite stellt die Austauscheinheit dar. Das Laden bzw. Nachladen einer Seite
erfolgt bei Bedarf, d.h. wenn eine in dieser Seite liegende Adresse referiert wird;
"demand paging".
Falls noch physische Seiten frei sind, wird einer neu zu ladenden logischen Seite
die nächste freie physische Seite zugewiesen. Sind alle physischen bereits
besetzt, muß eine logische Seite ausgelagert werden. --> Seitenwechsel.
Verantwortlich hierfür ist das Betriebssystem-Programm "Seiten-Supervisor".
Ein Programm kann seitenweise gestückelt im Arbeitsspeicher stehen, also ohne
Rücksicht auf irgendwelche logischen Grenzen an Seitengrenzen geteilt.
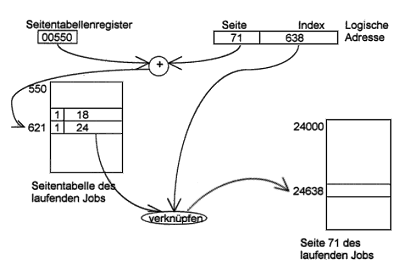
Die logische Adresse wird zerlegt in
- logische Seitennummer (Seitenadresse, höherwertiger Teil)
- Wortadresse (Zeilenadresse, niederwertiger Teil).
Die Wortadresse ist die relative Adresse zum Seitenanfang. Sie kann unverändert
in physische Adresse übernommen werden. Die Physische Adresse besteht auch aus
zwei Teilen:
- physische Seitennummer (Seitenadresse, höherwert. Teil),
- Wortadresse (niederwertiger Teil), die unverändert aus der logischen
Adresse übernommen wird.
Wegen der festen Seitengröße liegt auch die Grenze zwischen Wortadresse und Seitennummer
immer an der gleichen Stelle.
Die physische Seitennummer muß mittels der Adreßtransformation aus der logischen
Seitennummer ermittelt werden.
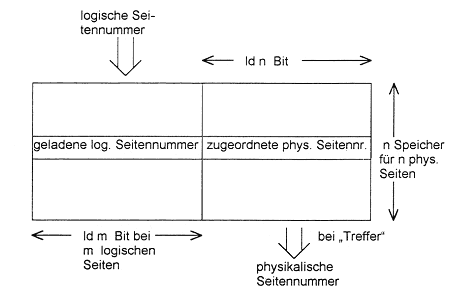
Die Adreßtransformation findet erst zum Zeitpunkt der Ausführung eines Befehls statt,
man spricht deshalb von einer dynamischen Adreßumsetzung. Sie geschieht i. a. unter
Verwendung einer Adreßumsetzungstabelle (Adreßumsetzungsspeicher, translation buffer),
die für die im Arbeitsspeicher befindlichen Seiten die Zuordnungspaare (log. Seitennummer,
phys. Seitennummer) enthält.
Besonders vorteilhaft für diesen Zweck sind sogenannte Assoziativspeicher (= CAM,
Content Addressable Memory), deren Zugriff nicht über eine Adresse, sondern über
Zelleninhalte erfolgt. Es wird ein Suchwort (Schlüssel) anstatt der Adresse angelegt
und als Ergebnis erhält man eine Trefferanzeige, u. U. auch keinen Treffer. Der
Schlüssel ist in diesem Fall die logische Seitennummer, 'Treffer' bedeutet, es
existiert ein entsprechender Eintrag in der Tabelle, im speziellen Fall der
Adreßumsetzung: die gesuchte logische Seite ist geladen, die eigentliche Information
des Tabelleneintrags, die physische Seitennummer, wird ausgelesen.
Meldet der Assoziativspeicher keinen Treffer, (d. h. die Seite befindet sich nicht
im Arbeitsspeicher --> "Page Fault") so wird das Laden dieser Seite eingeleitet
(Seitenwechsel und Eintrag in die Tabelle!).
Vorteile des Paging-Verfahrens (gegenüber Segmentierung):
- keine Speicherzersplitterung: jede freie physische Seite kann jede logische Seite
aufnehmen.
- keine Suche nach einem "passenden Loch" im Arbeitsspeicher für eine neu zu ladende
Seite erforderlich. Macht die Software für die Durchführung des Seitenwechsels einfach.
- bedeutend weniger Zeitaufwand für den Transfer zwischen Sekundärspeicher und
Arbeitsspeicher.
- im Arbeitsspeicher können sich i. a. gleichzeitig mehr aktive Programme befinden.
(Arbeitsspeicher ist nicht durch selten oder gar nicht benötigte Programmabschnitte belegt).
Fazit: Paging ist für die Realisierung eines virtuellen Speicher-Systems geeigneter
als die Segmentierung.
Seitenwechsel-(Segmentwechsel-)-Algorithmen
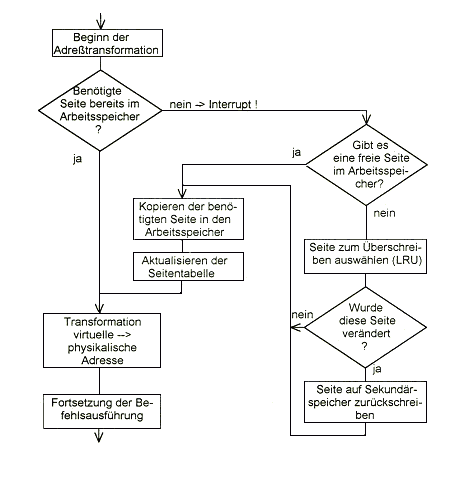
Kennzeichen der virtuellen Speichertechnik ist das Laden bzw. Nachladen von
Programmabschnitten (Seiten bzw. Segmente) bei Bedarf während der Programmausführung.
Grundvoraussetzung ihrer Realisierung ist deshalb die Fähigkeit der CPU, einen
laufenden Befehl zu unterbrechen (bei erforderlichem Nachladen einer Seite bzw.
Segments) und nach erfolgtem Nachladen den begonnenen Befehl erneut aufzusetzen und
dann ganz auszuführen.
Für die Auswahl derjenigen Seite (bzw. Segment) die bei einem Seitenwechsel aus dem
Arbeitsspeicher entfernt werden soll, gibt es verschiedene Strategien.
- Bei der verbreitetsten Strategie wird diejenige Seite (bzw. Segment), zu der am
längsten nicht mehr zugegriffen wurde, ausgewählt: "Least Recently Used" (LRU).
Hier wird davon ausgegangen, daß die Seite, die am längsten nicht benutzt wurde,
aller Wahrscheinlichkeit nach auch in Zukunft nicht benötigt wird.
- Seiten bzw. Segmente, in die nicht geschrieben wurde, deren Inhalt also nicht
verändert wurde, brauchen nicht in den Sekundärspeicher zurückgespeichert werden,
sondern können sofort durch die neue Seite überschrieben werden (Kennzeichnung durch
"dirty bit" in der Seitentabelle). Daraus ergibt sich eine Verkürzung der
Seitenwechselzeit!
|
| |
