 |
Wie funktionieren Suchmaschinen?
Zunächst jedoch erfahren Sie wie die Suchmaschinen an ihre Informationen kommen.
Die Kenntnis der verschiedenen Strukturen von Suchmaschinen ist die erste Voraussetzung
für eine erfolgreiche Recherche.Die wichtigsten Suchsysteme des Internet arbeiten mit zwei Verfahren:- gibt es die automatische Volltextindexierung von Intemet-Dokumenten (das machen zum Beispiel Alta Vista, HotBot, oder Infoseek)
- gibt es Dienste, die die Internet-Ressourcen systematisch, klassifikatorisch, oder hierarchisch aufgliedern (wie zum Beispiel Yahoo, DINO oder Web.de)Daneben existieren noch weitere Ansätze. So beschränken sich manche Dienste auf das Verzeichnen von Teilbereichen (wie zum Beispiel der Commercial Sites Index
auf Unternehmen im Internet). Andere Suchdienste setzen nicht auf eine
möglichst große Zahl indexierter Dokumente, sondern auf eine differenzierte
Bewertung dieser Dokumente (beispielsweise Magellan).
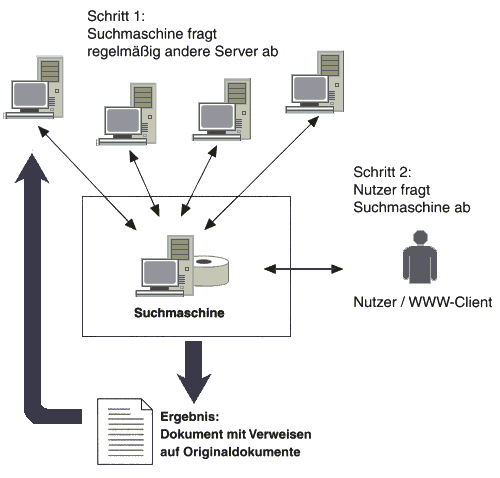
Bei der Volltext-Indexierung wird der gesamte Text der Web-Seiten indexiert. Die
Indexierung verläuft automatisch. Für den Input sorgen sogenannte Robots oder
Spider, was das gleiche meint, aber unterschiedlich heißt. Manchmal heißen die
Programme auch Agents. Spider sind Programme, die selbständig arbeitend
Ressourcen im Internet 'aufspüren', indem sie Verweisen (Hyperlinks) von
bereits bekannten Dokumenten folgen. Jedes neu von einem solchen Robot
gefundene Dokument wird automatisch in der Datenbank der Suchmaschine
verschlagwortet.
Wie dies geschieht, hängt vom einzelnen Robot ab; manche indexieren den
HTML-Titel oder die ersten Absätze eines Dokuments; andere durchforsten das
gesamte Dokument und indexieren buchstäblich jedes Wort.
Die meisten Suchmaschinen speichern die
gesammelten Dokumente nicht als komplette Spiegelung. Dazu bedarf es eines
gigantischen Rechen- und Speicheraufwandes, den derzeit nur Alta Vista betreibt.
Zur Suche wird eine Indextabelle angelegt, die die Worte einer Seite in einer
Ja-Nein-Struktur enthält.
| Dokumentname/Inhalt
|
Indiziertes Wort und gleichzeitig Suchwort (* = Ja, - = Nein) |
| |
Geld |
Macht |
Bauern |
Kuchen |
Schrank |
Schränke |
| Geld allein macht glücklich |
* |
* |
- |
- |
- |
- |
| Bauernmöbel und Schränke |
- |
- |
* |
- |
- |
* |
| Kuchen backen für Singles |
- |
- |
- |
* |
- |
- |
| Die Macht der Könige |
- |
* |
- |
- |
- |
- |
| Gebäck im Kühlschrank |
- |
- |
- |
- |
* |
- |
| Macht Kuchen dick? |
- |
* |
- |
* |
- |
- |
Mit Hilfe dieser Indextechnik läßt sich die Größe
der indexierten Dokumente auf ca. 4% reduzieren.
Hierdurch kommen verschiedene Eigenschaften der Suchmaschine zustande:
- Hohe Suchgeschwindigkeit, da in der Tabelle nur per Ja-Nein-Suche
auf das Vorhandensein des gesuchten Wortes abgefragt wird. Ja führt zu
Treffern, Nein entsprechend nicht
- Wortbedeutungen spielen keine Rolle. Bei der Suche nach 'Macht'
wird auch das Dokument 'Geld allein macht glücklich' gelistet,
obwohl es inhaltlich nichts mit dem Suchwort zu tun hat. Abhilfe würde in
diesem Fall die Eingabe des großgeschriebenen Suchwortes schaffen, sofern
die Suchmaschine Groß- und Kleinschreibung unterscheidet. Das Dokument 'Macht
Kuchen dick?', würde trotzdem als Treffer gelistet werden.
- Worte, die im Plural anders geschrieben werden, werden
nicht gelistet. 'Schrank' und 'Schränke' sind wegen des
Umlautes zwei verschiedene Worte.
- 'Kuchen' und 'Gebäck' sind zwar inhaltlich
eng verwandt, aber verschiedene Worte. Die Suche nach dem einen wird
keine Treffer beim anderen hervorrufen. Diese Verbindung schaffen nur 'menschliche'
Suchkataloge wie z.B. Yahoo.
Ein für die Abfrage bedeutsamer Unterschied liegt darin, ob die Suchmaschinen alle Begriffe,
auch sogenannte Stopwörter wie 'der', 'die', 'das', 'und', 'ob', 'ein', 'ich' indexieren,
oder ob sie sich auf sogenannte Schlüsselwörter beschränken, die wichtige
Informationen eines Dokumentes tragen. Beides hat Vor- und Nachteile:
Mit Suchmaschinen, die alle Begriffe indexieren, können Sie auch nach Phrasen
wie 'to be or not to be' suchen, eine Phrase, die - wenngleich klassisch - nur aus
Stopwörtem besteht. Andererseits verlängert die Indexierung aller Wörter die Dauer einer
Suchanfrage natürlich beträchtlich, weil die Datenmenge, die bei einer Anfrage
durchforstet werden muß, um ein Vielfaches größer ist.
Die einzelnen Suchdienste unterscheiden sich außerdem darin, wie weitgehend ihre
Robots und Spider Dokumente indexieren; sie unterscheiden sich in der
Indexierungsbreite (wie viele unterschiedliche Dienste/Server werden durchforstet)
und in der Indexierungstiefe (wie tief dringt ein Robot in die Angebots- und
Verzeichnisstruktur eines Webangebotes ein).
Software, die die Suchanfrage auswertet
Suchen Sie in einem auf Volltext-Indexierung basierenden Suchdienst nach einem
beliebigen Begriff, verweist die Suchmaschine auf alle Dokumente, die sie durchsucht
hat und die den gesuchten Begriff enthalten. Die Suchdienste geben als Ergebnis
gleich die URLs der gefundenen Dokumente als Hyperlinks aus, so daß Sie sofort
das gefundene Dokument aufsuchen können.
In vielen Fällen bekommen Sie jedoch nicht nur einen Treffer, je nach Suchbegriff
meldet Ihnen die Suchmaschine mehrere Tausend von Treffern. Um Ihnen die Auswahl aus
mehreren Treffern zu erleichtern, nehmen die meisten, auf Volltext basierenden
Suchmaschinen eine automatische Gewichtung der Suchergebnisse vor, das sogenannte
'Ranking'. Die Suchmaschine gewichtet die Ergebnisse auf der Basis eines
mathematischen Verfahrens, der unter anderem die Häufigkeit des gesuchten Begriffs
im Dokument bewertet. Es gibt keine generelle Gewichtung; jede Suchmaschine
verwendet zur Feststellung der Relevanz eines Suchtreffers unterschiedliche
Mechanismen. Im Suchergebnis erscheint die Liste der Treffer bei manchen
Suchdiensten nach Prozenten gewichtet. Bei anderen Suchdiensten stehen einfach
ohne weitere Angaben die 'besten' Treffer am Anfang.
Die verschiedenen Hauptaspekte sind:
- Anzahl der übereinstimmenden Wörter
Werden mehrere Suchworte verknüpft, so werden
Ergebnisse, die alle oder viele der gesuchten Begriffe oder Phrasen enthalten,
als relevanter eingestuft.
- Häufigkeit des Vorkommens von Suchbegriffen
Je öfter das Suchwort im Dokument vorkommt, desto
wichtiger wird es für den Gesamtinhalt des Dokumentes gewertet.
- Position des Vorkommens
- Domain und URL:
Auf Systemen, die lange Dateinamen zulassen, werden
Dokumente oft unter einem aussagekräftigen Namen gespeichert. Die
Indexierungssoftware wertet das Dokument bei Übereinstimmung mit dem
Suchwort als besonders relevant. Das gilt ganz besonders, wenn es sich um den
Domainnamen handelt
- Titel:
Ein Dokument, mit dem Suchwort im Titel hat gute Chancen auf
einen vorderen Platz.
- Überschrift:
Enthält eine Überschrift das gesuchte Wort, befaßt
sich das gesamte Dokument oder ein wesentlicher Teil damit.
- Meta-Tag:
Die Maschinen, die den Meta-Tag auswerten, ordnen Dokumente,
die den Begriff im Content (Inhalt) oder Keywords (Schlüsselworte) Tag führen,
höher ein. Die Praxis des Spamming von Meta-Tags hat leider um sich
gegriffen. Daher werden Dokumente, die ein Wort zu häufig im Meta-Tag
gelistet haben 'bestraft', indem sie nach hinten in die Liste
geschoben oder erst gar nicht dem Suchindex zugeführt werden.
- Dokumentenanfang:
Je früher das Wort im Dokument auftaucht, desto
relevanter für das Suchergebnis wird es gewichtet.
- Bezahlung:
Manche wenige Suchmaschinen setzen gegen Bezahlung bestimmte Links nach vorne.
Das Ranking grenzt zwar die Suchergebnisse ein, liefert aber dennoch in vielen
Fällen eine unübersichtliche Anzahl von Treffern mit über 90-prozentiger
Genauigkeit. Dabei ist allerdings keineswegs garantiert, daß die einzelnen
Ergebnisse wirklich alle mit dem zu tun haben, was Sie suchen. Selbst bei einer
Treffergenauigkeit von 99 Prozent kann es sein, daß es in der Fundstelle nicht
wirklich um die Frage geht, auf die Sie eine Antwort suchen.
Ein Beispiel: Wenn Sie die Web-Site des Bundesgerichtshofs in Karlsruhe suchen
und die Suchbegriffe 'BGH' und 'Karlsruhe' eingeben, erhalten Sie als Ergebnis
mit 99 Prozent Gewichtung für Ihre Fragestellung völlig uninteressante Dokumente,
in denen schlicht auf den BGH verwiesen wird oder bei denen die Abkürzung BGH im
Titel vorkommt.
|
|
|
