 |
Videodaten
AVI-Format von MicrosoftDas AVI (Audio Video Interleaved) Dateiformat ist eine spezielle Ausführung der von Microsoft für Windows 3.1 eingeführten Multimediaerweiterung: dem RIFF (Resource Interchange File Format). Es dient dazu, auf rekonstruierbare Art und Weise Audio-Videoinformationen zu speichern. Eine AVI-Datei besteht wie schon etliche Grafikformate) aus Chunks, alsoaus verschiedenen, ineinander verschachtelten Datenstrukturen. Sie können, jeder für sich, in weitere Strukturen (Sub-Chunks) unterteilt werden.Chunks beginnen mit einem Identifizierer (ID), der im FOURCC (Four Character
Code), d. h. in ASCII angegeben wird. Nach dem ID folgt eine Längenangabe,
die sich auf die folgenden Daten bezieht.
Der erste Chunk einer AVI-Datei hat den FOURCC 'RIFF', die ersten vier Bytes
der Daten des Chunks, der sogenannte Form-Typ, geben die Form der weiteren
Daten an, in diesem Fall steht hier 'AVI '. Die restlichen Daten werden in
zwei LIST-Chunks gespeichert (ID 'LIST'). Am Ende kann noch ein optionaler
Index-Chunk (ID 'idx1') enthalten sein, der die Vorgabe einer bestimmte
Abspielreihenfolge erlaubt.
RIFF
Microsoft führte mit den Multimediaerweiterungen für Windows 3.1 ein
Dateiformat ein, das noch heute angewendet wird: das Resource Interchange
File Format (RIFF). Es dient dazu, beliebige Multimedia-Ressourcen zu
speichern. Die einfachste Form einer AVI Datei wäre ein einziger
Videostream, meistens wird man aber dazu noch Audio-Informationen speichern
wollen.
Allgemein ist es möglich, auch spezielle Multimedia-Sequenzen wie etwa
einen MIDI-Track als zusätzlichen Datenstream in einer AVI-Datei
aufzunehmen. Um Audioinformationen in Stereoton zu sichern, benötigt man
dazu nur einen Stream, genauso als würde nur Mono gespeichert werden.
Weiterhin sind Control-Tracks möglich, etwa um externe Geräte zu
steuern.
RIFF-Dateien haben immer dieselbe Struktur, damit sie problemlos verarbeitet
werden können. Vergleichbar mit globalen und lokalen Prozeduren einer
höheren Programmiersprache bestehen RIFF-Dateien wieder aus einem
sogenannten Chunk (engl.: Klumpen, Happen, globale Prozedur), der wiederum
beliebig viele ineinander verschachtelte Subchunks (lokale Prozeduren)
enthalten kann. Der allgemeine Aufbau eines solchen (SUB-)Chunks besteht
aus drei Einträgen:
- ID: Identifizierer (Länge vier Byte)
- Size: Längenangabe (Länge vier Byte)
- Datenblock von 'Size' Bytes Länge
Für den Fall, daß die Länge der Daten in Byte ungerade ist, wird
rechts ein Füllbyte angehängt. Dem ID kann man entnehmen, um welche Art
von Daten es sich handelt. Er ist als FOURCC (Four Character Code)
gespeichert, wobei die vier Byte als ASCII-Zeichen interpretiert
werden. Die einzige ID mit dem ein RIFF-Chunk beginnen kann, ist 'RIFF'.
Unterschiede können dann nur noch in den IDs der Subchunks auftreten.
Hat eine Datenform einen ID mit weniger als vier ASCII-Zeichen Länge,
wird rechts mit Leerzeichen aufgefüllt.
Es ist möglich, sich FOURCC IDs (bestehend aus Großbuchstaben) bei
Microsoft registrieren zu lassen, der Lizenznehmer muß dann zu seinem
ID eine eindeutige Spezifikation des Formates der abgelegten Daten angeben.
Kleinbuchstaben werden bei FOURCC´s verwendet, die zu Subchunks gehören.
Es kann durchaus vorkommen, daß Chunks mit verschiedenen IDs Subchunks
haben, deren IDs identisch sind. Dies ist möglich, da die Interpretation
der Daten innerhalb der Subchunks nur im Zusammenhang mit denen des
übergeordneten Chunks vollzogen wird.
Innerhalb einer RIFF-Datei werden immer mindestens zwei Chunks vorhanden
sein: ein RIFF- und ein LIST-Chunk. Schon in den ersten vier Bytes der Daten
(Offset 8...12 der RIFF-Datei, dem sogenannten Form-Typ), wird die weitere
Form der Daten angegeben. Auch hier verwendet man wieder den FOURCC,
erwartungsgemäß trifft man an dieser Stelle bei einer AVI-Datei
auf die Zeichenfolge 'AVI '. Nach dem Form-Typ kommen die restlichen Chunks
der RIFF-Datei. Wie oben erwähnt ist immer auch noch ein spezieller Chunk,
der LIST-Chunk, enthalten (ID: 'LIST'). Die Daten eines LIST-Chunk
bestehen aus einer Typdefinition der Liste (Byte 0...3 der Daten des LIST
Chunk als FOURCC), den sogenannten List-Typ, gefolgt von aneinandergereihten
Chunks.
Beispiel für eine einfache RIFF-Struktur:
ID:[RIFF] Size:0x0000220 Form-Typ = [DEMO]
ID:[LIST] Size:0x0000214 List-Typ = [xyz ]
ID:[abcd] Size:0x0000100
ID:[efgh] Size:0x0000100.
AVI
Eine AVI-Datei hat als spezielle RIFF-Datei im Feld Form-Type des RIFF-Chunks
den Wert 'AVI '. Die restlichen Daten des RIFF-Chunk bestehen aus mindestens
zwei LIST-Chunks (ID 'LIST') gefolgt von einem optionalen Index-Chunk
(ID 'idx1'). Die erste Liste hat den List-Type 'hdrl', die zweite 'movi'.
In der 'hdrl'-Liste sind allgemeine Informationen zum
Chunk enthalten, sowie verschiedene Header, durch die das Format der
einzelnen Komponenten der AVI-Datei (Video, Audio, ..) angegeben wird.
Beispiel:
RIFF ('AVI '
LIST ('hdrl'
..
..
)
LIST ('movi'
..
..
)
['idx1'(AVI Index)]
)
Wichtige Subchunks einer AVI-Datei
Genauer besteht eine 'hdrl' Liste aus zwei Subchunks. Der erste hat den
ID 'avih' und definiert globale Eigenschaften der AVI-Datei, der zweite ist
ein LIST-Chunk mit dem List-Type 'strl' (Stream List), der
für jeden Stream mindestens zwei Chunks enthält: den 'strh'-
(Stream Header) und den 'strf'- (Stream Format) Chunk. Optional kann ein
'strd'- (Stream Data) Chunk folgen. Dieser dient dazu, zusätzliche
Daten zu speichern, er kann aber auch bei installierbarem
Komprimierer/Dekomprimierer als Initialisierungswert dienen und dabei
uninterpretiert an diese übergeben werden.
Beispiel: Subchunks im &Uunl;berblick
RIFF ('AVI '
LIST ('hdrl'
'avih'([Main AVI Header])
LIST ('strl'
'strh' ([Stream Header])
'strf' ([Stream Format])
'strd' (zusätzliche Header)
)
)
LIST ('movi'
(SubChunk: LIST ('rec '
SubChunk1
SubChunk2
)
)
['idx1' (AVIIndex)]
)
)
Im 'strh'-Chunk sind allgemeine Informationen zum Stream gespeichert,
beispielsweise, um welche Art von Daten (Bild oder Ton) es sich handelt,
welcher Kompressor benutzt oder mit welcher Rate digitalisiert wurde.
Im 'strf'-Chunk ist dann das genaue Format des Streams gespeichert.
Die der 'strl'-Liste folgenden Chunks in der 'hdrl'-Liste sind nicht genauer
spezifiziert.
Nach den Headern folgen im 'movi'-Chunk die eigentlichen Bild- und Tondaten.
Diese können Stream für Stream als Subchunks der 'movi'-Liste oder aber
ineinander verschachtelt gespeichert sein. Im ersten Fall existiert pro
Stream ein Subchunk, im zweiten Fall pro Schachtelung ein LIST-Chunk mit
dem Form Typ 'rec '.
Die 'movi'-Liste speichert dann letztlich die (eventuell komprimierten)
Daten für die einzelnen Bilder des Videos, sowie den (ebenfalls
möglicherweise komprimierten) Ton. Nach den eigentlichen Daten kann,
je nach Bedarf, der 'idx1' Chunk eingesetzt werden.
MPEG
Die Motion Picture Expert Group (MPEG) wurde Ende der 80er Jahre zur
Festlegung eines digitalen Standards für Bewegtbilddarstellung ins Leben
gerufen. Die MPEG-Verfahren definieren Normen für
Computer-gestützte Bewegtbilddarstellung, welche für die Bereiche
Heimanwendung (MPEG-1) und Studio (MPEG-2) entwickelt wurden. Zentraler
Bestandteil des MPEG_Codierungsalogorithmus ist die sogenannte
Bewegungskompensation. MPEG nutzt hierbei die Tatsache, daß sich zwei
aufeinanderfolgende Bilder derselben Filmszene in der Regel kaum
unterscheiden. Anstatt also zwei Vollbilder mit hohem Speicheraufwand zu
codieren, werden lediglich die veränderten Bilddetails erfaßt und
weiterverarbeitet. Verwendung finden hierbei drei verschiedene Bildtypen
(Intra-, Predicted- und Bidirectional predicted), welche sich in Funktion und
Codierung voneinander unterscheiden. Bis zur Verabschiedung der Norm
MPEG-1 standen bereits verschiedene Verfahren zur Verfügung
(Motion-JPEG (M-JPEG) und die Recommendation H.261 der CCITT).
Das M-JPEG-Verfahren basiert auf der Serialisierung von im JPEG-Format
komprimierten Einzelbildern. Die Qualität der verlustbehafteten
JPEG-Kompression ist dabei in weiten Grenzen konfigurierbar.
Der Kompressionsgrad liegt in der Einstellung für gute
Bildqualität bei einem Faktor von 20 - 25. Die Einbindung von Audiodaten ist
jedoch nicht im M-JPEG definiert. Ein Norm für M-JPEG existiert
nicht. Durch die Fixierung auf Einzelbildkompression erwies sich das Verfahren
als zu ineffizient.
Mit der Recommendation H.261 stand ein audiovisueller
Standard der CCITT zur Verfügung. H.261 besitzt durch seine Ausrichtung auf
Bewegtbildübertragung bereits einen hybriden Kompressionsalgorithmus, der
aus einer Spielart des Deltaverfahrens, einer Restbildkompression sowie einem
optional einbindbaren Verfahren zur Bewegungskompensation besteht. Der
Standard ist u. a. in Auflösung und Bildrate (7,5 - 30 Bilder/s)
konfigurierbar, wobei sich die Bandbreite im Bereich von 40 KBit/s bis zu
2 MBit/s bewegt. Die relativ enge Auslegung der
Recommendation erwies sich jedoch als starkes Handicap.
Eine Lösung für die oben aufgeführten Probleme steht mit MPEG-1
und MPEG-2 zur Verfügung, wobei wesentliche Merkmale von M-JPEG als auch
H.261 in die Normung eingingen. MPEG wurde dabei als generische Norm
entworfen, wodurch eine Anpassung an verschiedene Anwendungen möglich
gemacht werden soll.
Die ältere MPEG-1 Norm findet Anwendung in der PC-Welt und im
Unterhaltungsmarkt. Die Übertragungsrate liegt bei den dort üblichen
Auflösungen im Bereich bis zirka 1,5 MBit/s (192 KByte/s), wobei aus
praktischen Gründen die Grenzen des MPC-1-Standards (für
single-speed CD-ROM Laufwerke) eingehalten werden. Neben der CD-ROM eigenen
sich auch andere Medien als Basis für MPEG. Hierzu gehört das
DAT-System als auch die Verwendung in LANs zur Unterstützung
von Video-Mail oder Video-Übertragungen über Telefonleitungen (ISDN).
MPEG 2 wurde im Hinblick auf digitales Fernsehen definiert, es
unterstützt das Zeilensprungverfahren (Interlace). Die der Kompression
zugrundeliegenden Verfahren wie Bewegungskompensation, DCT, Quantisierung und
Huffman-Codierung sind für beide MPEG-Normen im Prinzip identisch.
Verbesserungen erfolgten lediglich auf Detailebene. MPEG 2 stellt also von
den Grundprinzipien her keinen größeren Fortschritt gegenüber
MPEG 1 dar, insbesondere löst MPEG 2 nicht MPEG 1 ab. So erreichen beide
Verfahren in der Regel identische Datenverdichtungen.
Die folgende Funktionen sollten innerhalb der Norm möglich sein
(soweit sie vom jeweiligen Medium unterstützt werden):
- wahlfreier Zugriff innerhalb des digitalen Videos
- schnelles Vor- und Rückwärtssuchen
- reverse play
- Audio-visuelle Synchronisation
- Fehlertoleranz
- Toleranz gegenüber Codierungs-/Decodierungsverzögerungen (wg. Kapazitätsengpässen)
- Editierbarkeit
- Formatflexibilität (in Größe und Bildwiederholfrequenz)
MPEG beschreibt, wie komprimierte Video- und Audio-Daten zu einem Bitstrom
zusammengefaßt werden. Die Norm umfaßt zwei Teile: die
Systemschicht und die Kompressionsschicht.
Diese Schichten haben ihrerseits wieder Teilschichten.
Die Funktion der Systemschicht definiert, auf welche Weise Bitströme von
Video- und Audio-Daten sowie optional privater Daten zu einem einzigen
Bitstrom zusammengefaßt werden. Außerdem werden Zeitmarken
(Presentation Time Stamp) bereitgestellt, die der synchronisierten Wiedergabe
von Bild und Ton dienen. Der maximale Abstand zwischen zwei Synchronisationspunkten
liegt bei 0,7 Sekunden. Die Systemschicht ist unterteilt in den Pack-Layer und den
Packet-Layer. Innerhalb eines Packs werden Packets aneinander gereiht.
Packets enthalten neben den Headerinformationen nur Daten einer einzigen Art,
also entweder Audio-Daten, Video-Daten oder private Daten
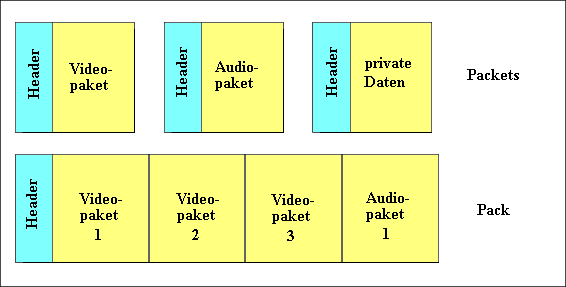
Diese Daten werden von den Kompressionsschichten für Video und Audio
codiert und zur Übertragung in die Päckchen eingefügt.
Das MPEG-Verfahren nutzt die Tatsache, daß in Folgen bewegter Bilder
zwischen aufeinanderfolgenden Bildern große Ähnlichkeit besteht. Mit der
Ausnahme krasser Szenenwechsel werden sich Bilddetails kontinuierlich von
einem Bild zum nächsten fortsetzen, wie zum Beispiel eine sich von links
nach rechts bewegende Person. Ein zentraler Bestandteil von MPEG ist nun die
sogenannte Motion Compensation: Die Bewegung der Person wird
einfach durch einen Vektor beschrieben, zum Beispiel durch die Angabe,
daß sie sich von einem Bild zum nächsten um 12 Pixel nach
rechts und 10 Pixel nach oben bewegt hat.

Die Erkennung eines
zusammengehörigen Objekts wäre in der Praxis allerdings viel zu
aufwendig. Stattdessen werden sogenannte Makroblöcke mit einer
Pixelgröße von 16 x 16 untersucht. Diese Makroblöcke entsprechen
vier Blöcken, wie sie bei JPEG codiert werden. Im nächsten
Schritt wird die Differenz aus dem realen Makroblock in Filmbild 1 und dem
verschobenen Makroblock aus Filmbild 2 gebildet, Dieses Fehlerbild muß
neben dem Verschiebungsvektor zur Beobachtung der Fehlerfortpflanzung codiert
und gespeichert werden. Der geringste Speicheraufwand entsteht natürlich,
wenn der Unterschied zwischen den verschobenen Makroblöcken und den
tatsächlich dargestellten Blöcken so klein ist, daß auf die
Codierung der Differenz ganz verzichtet werden kann.
MPEG steuert die Darstellung von komprimiertem Video durch die Festlegung
einer Syntax. Die Regeln zur Erfassung der Bewegungskompensation lassen
hingegen viele Freiheiten zu, so daß die Qualität des MPEG-Endprodukts
auch maßgeblich von der Güte des verwendeten Codierungs-Algorithmus
abhängt.
Die MPEG-Bildtypen
MPEG verwendet drei Frames (Bildtypen):
- I-Frame (Intra Frame)
- P-Frame (Predicted Frame)
- B-Frame (Bidirectional predicted Frame)

I-Frames (intracodierte Bilder) verwenden nur Informationen aus einem
einzigen digitalisierten Vollbild. Bei I-Frames findet die 'Motion
Compensation' somit keine Anwendung. Sie dienen aber als Ausgangspunkt
für die Ermittlung von P- und B-Frames. Der Kompressionsfaktor
beträgt typisch 7:1.
P-Frames werden durch 'Motion Estimation' aus zeitlich zurückliegenden
Bildern vom Typ I oder P abgeleitet. Auch P-Frames dienen demnach als
Referenzbilder für die Ermittlung von Verschiebungsvektoren. Der
Kompressionsfaktor beträgt typisch 20:1.
B-Frames werden entweder aus früheren oder späteren P- bzw. I-Frames
abgeleitet oder auf Basis von Nachbarbildern interpoliert. Sie dienen niemals
zur Berechnung von Motion-Vektoren. Daher tragen B-Frames im Gegensatz zu
P-Frames nicht zur Fehlerfortpflanzung bei. MPEG-Encoder haben darauf zu achten,
daß ein gewisses Datenbudget eingehalten wird, um den Decoder (bzw. das
Speichermedium) nicht zu überlasten. Bei B-Frames darf wegen der fehlenden
Fehlerfortpflanzung mit weniger Bits codiert werden als bei P-Frames, so
daß die Verwendung von B-Frames auch zur Regulierung des Bitstroms dienen
kann. Der Kompressionsfaktor beträgt typisch 50:1.
I-Bilder erhalten die Zugriffsfreiheit auf das komprimierte
Videomaterial, weil die Bildinformationen nicht über mehrere Bilder
verteilt sind. Ein typisches Muster für die Abfolge von I-, P- und B-Frames
ist die Abfolge
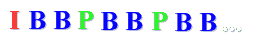
Zur bildgenauen Positionierung ist somit eine Berechnung über maximal
sechs Zwischenbilder erforderlich. Die Kompressionsmethode der Makroblöcke,
aus denen I- und P-Frames aufgebaut sind, basiert auf der Huffman-codierten
quantisierten DCT auf 8 x 8 Pixelblöcken (4 Blöcke = 1 Makroblock),
wie sie bei JPEG Verwendung findet.
Die Berechnung der Bewegungskompensation (Motion Compensation) ist sehr aufwendig.
Bei Software-Encoding, auch 'Non Real Time MPEG Encoding' genannt, kann die
Codierung auf Standardprozessoren meist nicht in Realzeit erfolgen.
MPEG-Bewegungskompensation
Bewegungskompensation bedeutet, daß redundante Bildinformationen, welche
sich durch Koordinatenverschiebungen innerhalb einer Bildsequenz ergeben, nur
durch einen Vektor mit Referenzierung auf einen Urblock codiert werden.
Bei der Berechnung der Motion Compensation wird sich dabei jedoch ein Bilddetail
nicht immer identisch über eine Folge mehrerer Bilder fortsetzen. Ein
Pixelblock wird sich im Fall von Realvideo aufgrund des Grundrauschens immer
mehr oder weniger vom vorhergehenden unterscheiden. Bei einer Person, die sich
durch das Bild bewegt, ändert sich zum Beispiel der Sitz oder die Schattierung
der Kleidung. Falls die Bildunterschiede signifikant sind, muß neben dem
Motion-Vektor auch noch ein Fehlerbild codiert werden. Die Entscheidung, wohin
sich ein Bildinhalt bewegt, kann nur aufgrund objektiver Kriterien erfolgen.
Ein Video-Encoder wird daher in der Umgebung des früheren Ausgangsblocks
nach einem Pixelblock suchen, der eine größtmögliche Ähnlichkeit
besitzt.
Ein denkbares Entscheidungskriterium ist zum Beispiel der
mittlere quadratische Abstand der Werte der beiden 16 x l6-Pixelblöcke.
Gemeint ist damit, daß die Quadrate der Differenzen aller Luminanzwerte
und Chrominanzwerte des Originalblocks und des Kandidatenblocks innerhalb des
Suchbereiches errechnet und aufsummiert werden. Auf diese Art und Weise
erhält man ein Maß für die Ähnlichkeit zweier Blöcke.
Hat sich ein Block zum nächsten fortgepflanzt ohne sich zu verändern, ist
die Differenz gleich Null. Eine sehr rechenaufwendige Methode wäre, für
alle denkbaren Verschiebungen innerhalb des Suchbereichs die Summe der
quadrierten Differenzen zu bilden. Im Encoder wird dann der Bewegungsvektor
des Bildes mit dem kleinsten quadratischen Abstand zum Original als der beste
ausgewählt. Die Suche nach dem besten Motion-Vektor kann mit einer
Auflösung von 1 oder 1/2 Pixel erfolgen. Die für die
Codierung verwendeten Vektoren besitzen dabei eine Auflösung von bis zu
einem halben Pixel. Für die Suche nach dem Motion-Vektor kann linear
zwischen benachbarten Pixeln interpoliert werden. Da der Rechenaufwand sehr
groß ist, werden unterschiedliche Suchstrategien angewandt. So kann
beispielsweise zunächst das Gitter der 48 x 48 ganzzahligen Verschiebungen
abgesucht werden, um danach die acht benachbarten Positionen zu untersuchen.

Eine andere Methode benutzt für die Suche zunächst ein grobes Raster mit
einem Abstand von mehreren Pixeln um es dann um die beste Position nach und nach
zu verfeinern. Diese Methode kommt mit noch weniger Schritten aus. Allerdings
wird die Wahrscheinlichkeit geringer, den optimalen Motion-Vektor zu finden.
Reduktionsmethode bei Real-Video
Ein digitalisiertes Videobild muß für MPEG-1 vorbereitet werden, um
zu handhabbaren Datenmengen zu kommen (Übertragungsrate bis zu 1,5 MBit/s).
Die üblichen Auflösungen von digitalisiertem Video sind 720x480 Pixel
bei 60 Hz (NTSC) oder 720x576 Pixel bei 50 Hz (PAL), wobei das Material in
YCbCr-4:2:2-Form vorliegt. Diese Auflösung wird in horizontaler und
vertikaler Richtung um die Hälfte verringert. Die horizontale
Auflösung wird dabei i. A. nicht einfach durch Weglassen von
Luminanz- oder Chrominanzwerten verringert. Gebräuchlich ist eine
gewichtete Mittelung eines Pixels mit seinen später nicht mehr verwendeten
Nachbarpixeln. In vertikaler Richtung kann eine ähnliche Filterung
erfolgen, oder es wird einfach jede zweite Zeile weggelassen, also nur ein
Halbbild verwendet. Die Chrominanz-Auflösung wird in vertikaler Richtung
ein weiteres Mal durch Filterung halbiert, so daß ein 4:2:0
Abtastungsmuster entsteht. Vier Abtastpunkte der Lunimanz entsprechen
hierbei einem Abtastpunkt für die Chrominanz. Die einzelnen Abtastwerte
werden wie bei JPEG zu 8 x 8-Matrizen zusammengefaßt, vier der
8 x 8-Blöcke bilden einen Makroblock. Die Farbinformation wird mit je einer
8 x 8- Matrix für Cr und Cb dargestellt, so daß pro Makroblock
insgesamt sechs 8 x 8-Matrizen verwendet werden.
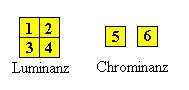
Die Auflösungsreduzierung wird in Dezimierungsfiltern entweder im
MPEG-Prozessorbaustein oder in Videodigitalisierung-Bausteinen vorgenommen.
Bei der Darstellung komprimierten Videomaterials muß umgekehrt die
anfängliche Auflösung wiederhergestellt werden. Dazu werden zwischen
den Luminanz- bzw. Chrominanzwerten Nullwerte eingefügt, und anschließend
eine gewichtete Mittelung durchgeführt. Die Gewichte sind die
Filterkoeffizienten eines Interpolationsfilters. So wird zum
Beispiel aus der Folge
10, 11, 12
die Folge
10, 10.5, 11, 11.5, 12
erzeugt. Einfachere Verfahren zur Interpolation arbeiten mit der Wiederholung
von Werten.
Die MPEG-Syntax
Die MPEG-Syntax beschreibt, auf welche Weise die zur Verfügung stehenden
Daten in hierarchischer Weise (Schichten) miteinander verknüpft werden.
| Sequence-Layer |
Diese Schicht dient der Zusammenfassung einer oder mehrere Bildgruppen.
Im zugehörigen Header werden allgemeine Parameter gespeichert.
Konkret sind dies Bild-Breite, Bild-Höhe, Bildformat (z. B. 4:3),
Bildwiederholrate (pps), Übertragungsrate und Puffergröße.
|
|---|
Group-of-Picture-
(GOP-)Layer |
Oberhalb der Picture-Ebene wird in der GOP-Ebene eine beliebige Anzahl
von Bildern in natürlicher Abfolge zu Gruppen von Bildern zusammengefaßt.
In jeder Gruppe muß mindestens ein I-codierter Frame enthalten sein.
Sogenannte geschlossene Gruppen können decodiert werden, ohne daß
für die Motion-Compensation auf die vorherige GOP Bezug genommen werden
muß; sie ist ohne jeden anderen Bezug für sich
decodierbar. Der GOP-Header spezifiziert unter anderem, ob Standard-
oder anwenderdefinierte Quantisierungsmatrizen zur Anwendung kommen. Der
Encoder darf diese Informationen vor jeder Bildgruppe wiederholen, um einen
wahlfreien Zugriff zu erleichtern, die Quantisierungsmatrizen dürfen dabei
sogar geändert werden.
|
|---|
| Picture-Layer |
Diese Schicht enthält alle Informationen, die zum Decodieren eines Bildes
benötigt werden. Der Header enthält die Information, als wievieltes Bild
der entsprechenden 'Group of Pictures' (GOP) das Bild dargestellt werden soll.
Diese Angabe ist notwendig, da wegen der Ruckwärtsbezüge bei B-Frames
der Decoder die Bilder in einer anderen Reihenfolge benötigt als es der
natürlichen Reihenfolge entspricht.
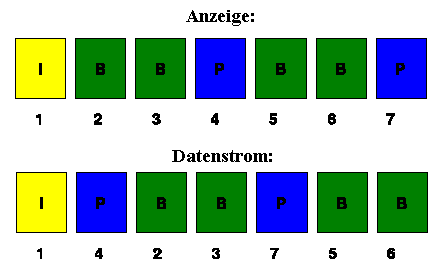
Außerdem wird beschrieben, um welche Art von Frame (I, B oder P) es sich
handelt und ob die Verschiebungsvektoren mit einer Genauigkeit von einem oder
einem halben Pixelabstand dargestellt werden.
|
|---|
| Slice-Layer |
Slices sind Streifen von aufeinanderfolgenden Makroblöcken. Ein Decoder
kann jedes Slice getrennt decodieren, ohne auf andere Slices zurückgreifen
zu müssen. Auf diese Weise wird verhindert, daß sich bei
Übertragungsfehlern eine Störung über das ganze Bild fortsetzt.
Mit Beginn des nächsten Slices werden wieder korrekte Daten geliefert.
Slices müssen nicht an der rechten oder linken Bildkante beginnen, sondern
können mit beliebig positionierten Makroblöcken beginnen oder
aufhören.
|
|---|
| Makro-Layer |
Hier wird beschrieben, wo der Makroblock im Bild liegt, und um welche Art
von Makroblock es sich handelt (I, B oder P). Der Encoder hat bei P- und B-Frames
eine Reihe von Entscheidungen auf der Makroblock-Ebene zu treffen, die
maßgeblich für den Platzbedarf des codierten Bildes sind. Bei
P-Frames ist zunächst festzulegen, ob Motion Compensation
angewendet wird. Danach ist zu entscheiden, ob der Makroblock wegen zu
großer Fehlerfortpflanzung intracodiert wird. Falls ein
Verschiebungsvektor verwendet wird, muß desweiteren geklärt werden, ob
das Fehlerbild codiert wird. Bei B-Bildern ergeben sich drei Ableitungsmöglichkeiten
für den Makroblock: die Ableitung aus zurückliegenden oder
zukünftigen Referenzbildernund schließlich eine
Kombination beider Möglichkeiten (Average). Bei letzteren werden die
Luminanzwerte im Encoder durch Mittelung errechnet. Der Encoder darf nicht mehr
Bits pro Sekunde generieren als der Decoder später verarbeiten kann
bzw. als der Kommunikationskanal übertragen kann.
|
|---|
| Block-Layer |
Auf dieser Ebene wird ein Block von 8 x 8
Pixeln mit Original- bzw. Fehlerbildinformation in Form von quantisierten und
Huffman-codierten DCT-Koeffizienten dargestellt (siehe auch JPEG). Der in
den DCT-Matrizen am unmittelbarsten ins Auge fallende Unterschied zwischen
Original- und Fehlerbildern ist das Vorzeichen der Luminanzwerte und der
Chrominanzwerte. Während diese Werte im Original stets positiv sind, ergeben
sich bei der Differenzbildung positive und negative Werte. Die Differenzwerte
werden in einer anderen Art und Weise quantisiert, da die psychovisuellen
Gewichtsfunktionen für die Differenzen zweier realer Bilder keine
augenfällige Bedeutung haben. Für die Fehlerbilder wird eine
Quantisierungskennlinie verwendet, die um den Nullwert herum in einem doppelt
so breiten Intervall wie an allen anderen Stellen den Wert Null erzeugt. Das
bedeutet in der Praxis, daß der Encoder bei nur geringen Unterschieden
von Helligkeit und Farbsättigung keinen Unterschied codiert.
|
|---|
|
|
|
