 |
Aufbau von HTML-Dokumenten
HTML-Dokumente sind Text-Dateien, die spezielle Steuer- und Formatierbefehle,sogenannte Tags enthalten. Ein HTML-Tag besteht aus einem Namen und (optionalen) Parametern.Es ist eingeschlossen von < und >. Alle Tags, die nicht leer sind, also beispielsweise Text enthalten, benötigen weiterhin ein Ende-Tag, das von </ und > eingeschlossen ist. Solche Konstrukte werden auch "Container" genannt. Die Groß/Kleinschreibung spielt bei Tags keine Rolle.Ein HTML-Dokument wird eingeleitet durch <HTML> und abgeschlossendurch </HTML>.
Innerhalb des Dokumentes gibt es den Kopfteil, begrenzt durch
<HEAD> und </HEAD>, der nur einige ausgewählte
administrative Daten enthält, und den Hauptteil, begrenzt durch
<BODY> und </BODY>. Innerhalb des Hauptteils
befinden sich sämtliche Informationen und Auszeichnungen die das Dokument
strukturieren.
Im HEAD-Tag sind unter anderem enthalten:
- <TITLE>
- Dieses Tag gibt den Titel des Dokumentes an, dieser sollte
kurz und aussagekräftig sein. Er Erscheint in der Kopfzeile des
Browser-Fensters und wird auch für die Indizierung von HTML-Dokumenten
herangezogen.
- <ISINDEX>
- Gibt an, daß an das Dokument Suchanfragen gestellt werden
können; dieses Tag wird normalerweise vom Server automatisch generiert, wenn er
Suchanfragen verarbeiten kann.
- <BASE>
- Gibt den Pfad an, in dem sich das Dokument befindet. Dies
ist dann von Nutzen, wenn im Dokument Referenzen ohne volle Pfadangabe
existieren und das Dokument einmal nicht innerhalb des üblichen Kontextes
gelesen wird.
- <LINK>
- Gibt die URLs von anderen Dokumenten an, zu denen dieses
Dokument eine Beziehung aufweist.
- <NEXTID>
- Ermöglicht es, eine Variable zur Dokumentenverwaltung
zu definieren.
- <META>
- Sogenannte META-Tags enthalten Infos über Autor und Dokument,
den Zeichensatz, Stichworte und ähnliches.
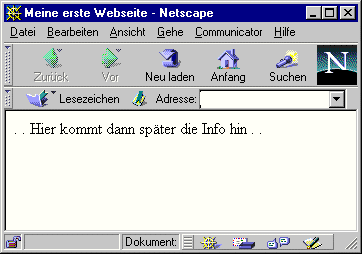
Damit haben wir schon das Grundgerüst eines HTML-Dokuments:
<HTML>
<HEAD>
<TITLE>Meine erste Webseite</TITLE>
</HEAD>
<BODY>
.
.
Hier kommt dann später die Info hin
.
.
</BODY>
</HTML>
Im Fenster des Browsers sieht das noch recht dürftig aus:
Was ist ein URL?
URL steht für Uniform Resource Locator. Ein URL ist eine Referenz auf
eine Datei oder sonstige Ressource. Diese Referenz wird benötigt, um
Verweise auf andere Stellen im aktuellen Dokument, auf andere Dokumente auf
dem aktuellen Server oder um andere Dokumente auf anderen Servern anzugeben.
Darüber hinaus kann mit einem URL auch ein Internet-Dienst spezifiziert
werden. URLs dienen auch zum Einbinden von Grafiken oder anderen multimedialen
Objekten.
Das Aufbau-Schema eines URLs ist
Dienst://Host.Domain:Port/Pfad/Dateiname
Die Angabe des Ports kann entfallen, es wird dann der für den
angegebenen Dienst definierte Standardport verwendet. Ebenso können
Host und Domain entfallen, wenn es sich um den lokalen Server handelt. Auch
der Pfad kann weggelassen werden, wenn sich die gesuchte Datei im aktuellen
Verzeichnis befindet. Grundsätzlich sollten bei Links auf lokale Dateien
die Angaben von Host und Domain weggelassen werden, da sonst jedesmal eine
(unnötige) Nameserveranfrage erfolgt.
Wenn die WWW-Dokumente nicht auf dem Server selbst entwickelt werden, kann
es häfig vorkommen, daß sich die Pfade von Entwicklungsrechner
und Server unterscheiden. In diesem Fall kann man gut mit relativen Pfade
arbeiten, die beim Zugriff auf die Seiten vom Server automatisch in absolute
Pfadangaben umgesetzt werden.
Als Dienste werden viele Internet-Dienste unterstützt. Die wichtigsten sind
- http
- Dies gibt eine Datei oder ein Verzeichnis auf einem WWW-Server an.
- file
- Gibt eine lokale Datei an.
- ftp
- Gibt eine Datei oder ein Verzeichnis auf einem FTP-Server an. Standard
ist anonymer ftp. Will man einen Usermnamen angeben, muß man diesen
getrennt durch '@' vor dem Host angeben.
- mailto
- Erlaubt es, eine e-mail zu versenden.
- news
- Gibt eine Newsgruppe auf einem News-Server an.
Weitere Dienste, auf die ein URL verweisen kann sind WAIS, telnet, tn3270 oder
Gopher.
Browser
Der Begriff Browser kommt aus dem Englischen "to browse" und bedeutet soviel wie
schmökern oder blättern. Hierbei handelt es sich um ein Programm, mit
dem es möglich ist, die Seiten des World Wide Web multimedial darzustellen
und anzuschauen. Der Browser ist also ein Werkzeug zur komfortablen und bequemen
Darstellung von Texten, Grafiken, Sprache oder Musik. Der Browser wurde speziell
für den WWW-Dienst entwickelt, der auf einem Hypertextsystem basiert, womit
es möglich ist, mittels sogenannter "Hyperlinks" von einem WWW-Angebot zu
einem anderen zu springen.
Ein Hyperlink ist nichts weiter als ein Querverweis, der entweder auf irgendeine
anderen Stelle im gleichen Dokument, auf ein anderes Dokument des gleichen
Anbieters oder auf ein Dokument eines anderen Anbieters irgendwo auf der Welt
verweist. So sind die unterschiedlichsten Dokumente weltweit miteinander
vernetzt, eben ein "weltweites Gewebe". Jedes Dokument hat eine eindeutige
Adresse, den sogenannten URL (Uniform Resource Locator), unter dem es direkt
aufgerufen werden kann. Dies erfolgt durch Eintippen des URL in das Eingabefeld-Feld
im oberen Bereich des Browser-Fensters. Im Text eingebaute Querverweise sind meist
unterstrichen und werden in einer anderen Farbe angezeigt. Querverweise können
sich aber auch hinter Bildern verbergen. Wenn man mit dem Mauszeiger über die
WWW-Seite fährt und auf einen Querverweis trifft, wird der Cursor zur Hand und
die Adresse des Querverweises im unteren Fensterrahmen eingeblendet.
Die Informationen selbst liegen als strukturierte Textdokumente vor, die im HTML-Format
(HTML=Hypertext Markup Language) kodiert sind. Der Browser interpretiert die
HTML-Kodierung und stellt die WWW-Seite für den Benutzen optisch ansprechend dar.
Da sich die Fähigkeiten der WWW-Angebote permanent weiterentwickeln, besteht die
Möglichkeit, seinen Browser der technologischen Entwicklung ständig anzupassen.
Hierzu gibt es sogenannte "Plug-Ins". Ein Plug-In ist ein Programm, das die multimedialen
Fähigkeiten der Browser erweitert (z.B.: Real Audio Player, Shockwave (Flash),
Acrobat Reader, Quicktime Movie Player, etc.) Ein Browser ist somit ein offenes System,
das durch die Plug-Ins erweitert wird. Die gängigsten Browser sind der Microsoft
Internet Explorer, der Netscape Communicator und Opera, wobei von den beiden letztgenannten
Browsern nicht nur Windows-Versionen, sondern auch Produkte für UNIX und Linux zur
Verfügung stehen. Diese konkurrierenden Produkte werden oft auf CDs, die in
Computer-Fachzeitschriften enthalten sind, mitgeliefert oder können kostenlos aus
dem Internet heruntergeladen werden.
Der Cache-Speicher des Browsers dient zum vorübergehenden Speichern einer angeforderten
WWW-Seite im Arbeitsspeicher oder auf der Festplatte des eigenen Rechners. Wird eine
WWW-Seite angefordert, so prüft der Browser zunächst, ob diese Seite nicht schon einmal
abgerufen wurde und noch im Cache abgelegt ist. Ist dies der Fall, so kann er eine Kopie
dieser Seite viel schneller aus dem Cache (d.h. von der eigenen Festplatte) holen, als
wenn er sie erneut vom Server anfordern würde. Will man verhindern, daß eine erneut
angeforderte WWW-Seite aus dem Cache-Speicher gelesen wird (weil man z.B. weiß,
daß die Originalseite verändert wurde), so kann man mit der Aktualisieren-Funktion
dem Browser mitteilen, daß die entsprechende Seite erneut vom WWW-Server zu holen
ist. Der Cache-Speicher hat eine definierte Größe. Ist er voll, so werden
sukzessive mit den neu hinzukommenden Seiten die am längsten darin gespeicherten
Seiten gelöscht. Will man beim Netscape Communicator wirklich alles neu laden
(was wichtig beim Testen von Frames ist) muß man beim Anklicken der Schaltfläche
die Shift-Taste gedrückt halten.
|
|
|
