 |
Programmunterbrechungen
Programmunterbrechungen können durch Signale aus der Rechnerumgebung (z.B.
vom gesteuerten Prozeß) ausgelöst werden, um quasi "die Aufmerksamkeit"des Rechners auf sich zu lenken. Insbesondere auf dringende, aber relativ seltenauftretende Ereignisse können so die entsprechenden Programme (Interrupt ServiceRoutinen) schnell reagieren.
In der Regel führt die Ablaufsteuerung nach der Beendigung des gerade ausgeführtenBefehls die Programmunterbrechung durch und setzt nach der Abarbeitung der InterruptService Routine (ISR) das unterbrochene Programm fort.
Die Aufgaben der Interruptbehandlung im einzelnen: - Aufnehmen und Überprüfen der Unterbrechungsanforderung:
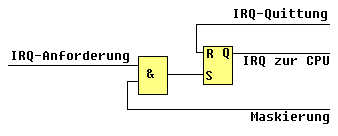
Im einfachsten Fall hat das Unterbrechungswerk nur eine einzige Eingangsleitungfür die Unterbrechungsanforderungen. Diese führt auf ein Flip-Flop, dasdurch ein Anforderungssignal auf 1 gesetzt wird und bei Bedienung des Interrupts sofort wieder gelöscht werden muß um evtl. weitere Interrupt-Anforderungenaufnehmen zu können. Dieses FF ist notwendig, um die zu beliebigen Zeitpunktenankommenden Interrupt-Anforderungen (Interrupt-Request) so lange zu speichern, bis sievom Leitwerk am Ende der Befehlszyklen abgefragt werden. Häufig darf jedoch eine Interrupt-Anforderung nicht sofort zur Unterbrechung führen,z.B. während der Ausführung zeitkritischer Programmabschnitte. Eine einfacheMöglichkeit besteht in der "Maskierung" des Signals mit Hilfe einesMasken-FF's und eines Gatters. Nur wenn das Masken-FF gesetzt ist, führt eine"anstehende" Unterbrechungsanforderungauch zu einem Interrupt. Das Masken-FFkann i.a. durch Maschinenbefehle gesetzt und gelöscht werden ("enable"bzw. "disable interrupt").
- Identifizierung des Interrupt-Verursachers:
Typische Anwendungen mit mehreren Quellen für Interrupt-Anforderungen verlangen,
daß für jedes Signal auch ein spezifisches Unterbrechungs-Bearbeitungs-Programm
(ISR = Interrupt Service Routine) vorhanden ist, da ja auf jedes Signal anders
zu reagieren ist. Damit ergibt sich das Problem der Interrupt-Identifizierung als
Voraussetzung für die Zuordnung der richtigen ISR und für das Löschen
des richtigen Interrupt-Anforderungs-Flip-Flops.
Die beiden wichtigsten Grundprinzipien der Interrupt-Identifizierung sind:
- Polling: Der Interrupt-Verursacher kann sich nicht selbst zu erkennen geben;
am Prozessor erscheint lediglich das Anforderungssignal und es ist die Aufgabe
des Interrupt-Bearbeitungs-Programms, über eine Kette von Abfragen an die
in Frage kommenden Peripherie-Bausteine, den aktuellen Interrupt-Verursacher herauszufinden.
Mit "Abfragen" ist hier das Lesen der Statusregister der Peripheriebausteine
gemeint, in denen die Tatsache der Interrupt-Anforderung jeweils in einem bestimmten
gesetzten Bit (Interrupt-Request-Bit) vermerkt ist.
- Interrupt-Vectoring: Der Interruptverursacher liefert (im Zuge der Bussequenzen
bei der Interrupt-Annahme durch den Prozessor) einen "Kenn-Code" mit ab (meist
über den Datenbus), an dem der Prozessor erkennen kann, um welchen Interrupt
es sich handelt. Dieser sogen. "Interrupt-Vektor" wird i.a. gleich als
(indirekte) Startadresse der zugehörigen ISR verwendet. Damit entfällt
das zeitraubende Abfragen, die sogenannte Interrupt-Reaktionszeit wird kürzer.
- Vorrangsteuerung der Interruptverursacher:
Nicht alle Interrupts sind mit der gleichen Dringlichkeit zu bearbeiten; so muß
z.B. die Interrupt-Anforderung, die den Zusammenbruch der Netzspannung anzeigt, vorrangig
behandelt werden gegenüber einer Interrupt-Anforderung, die lediglich zur Übernahme
eines Datenwortes von einer Eingabeschnittstelle auffordert.
- Retten und Rückspeichern des Prozessorzustandes:
Wenn eine Programmunterbrechung ausgeführt werden soll, so muß auf jeden
Fall der Zustand des Prozessors gerettet werden. Denn das Interrupt-Service-Programm
benutzt ja ebenfalls den Prozessor und verändert dabei dessen Zustand. Soll
anschließend das unterbrochene Programm fortgesetzt werden, so ist es unbedingt
nötig, vorher den Zustand wieder herzustellen, wie er bei Auftreten der Unterbrechung
herrschte.
Die Prozessorzustände, die während einer Befehlsausführung durchlaufen
werden, sind nur sehr aufwendig zu beschreiben (z. B. mitten in einer Multiplikation).
Entsprechend groß wäre der Aufwand zur Rettung des Prozessorzustandes,
wenn man Unterbrechungen mitten im Befehlszyklus zuließe. Man läßt
deshalb Unterbrechungen i. a. nur am Ende eines Befehls zu, denn dann ist der Prozessorzustand
vollständig durch den Inhalt der Prozessorregister definiert.
In einer typischen Interrupt-Service-Routine werden die Inhalte von Prozessor-Registern
verändert. Aber selbst wenn keine derartigen Befehle in der ISR vorkommen,
so müssen doch zumindest zwei Register gerettet werden: der Programmzähler
und das Prozessor-Status-Register, denn die Inhalte dieser Register ändern
sich in jedem Fall. Man bezeichnet diese beiden Register auch als "Zustandsvektor".
Die einfachste Möglichkeit, den Zustandsvektor zu retten, besteht darin, ihn
in bestimmte reservierte Speicherzellen zu schreiben, und ihn von dort nach Beendigung
der ISR wieder zu lesen. Dies hat den offensichtlichen Nachteil, daß keine
Verschachtelung (Nesting) von Programmunterbrechungen möglich ist, d.h. man
müßte das Unterbrechen einer ISR verbieten, weil sonst der gerettete
Zustandsvektor überschrieben würde.
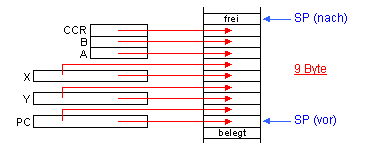
Wesentlich besser eignet sich zum Retten des Zustandsvektors ein sogenannter Kellerspeicher
(engl. stack, oder auch LIFO = last in first out).
Das Stackprinzip kann hardwaremäßig realisiert sein (spezielle Chips)
oder in einem reservierten Bereich des normalen Arbeitsspeichers nachgebildet
sein. Zu diesem Zweck existiert ein Zeigerregister, das immer den letzten Eintrag
im Stack adressiert (Stackpointer zeigt immer auf den "Top of Stack",
d.h. auf den letzten Eintrag).
Mit jeder neuen (geschachtelten) Programmunterbrechung wächst der Kellerspeicher
um die entsprechenden Einträge, mit jedem Rücksprung in ein vorher unterbrochenes
Programm reduziert er sich wieder entsprechend, so daß das zuletzt unterbrochene
Programm nach Beendigung des laufenden wieder aufgenommen wird. Der Stack wächst
und schrumpft mit jedem Eintreten/Verlassen von ISRs, man sagt, der Stack "pulsiert".
Häufig müssen außer den beiden o.g. Registern (PC und Prozessor-Status-Register)
auch noch andere gerettet und rückgespeichert werden, nämlich dann, wenn
sie von der ISR verändert werden. Auch hier bringt die Verwendung eines Stacks
die gleichen Vorteile wie oben erwähnt. Da diese Register jedoch nicht immer
gerettet werden müssen besteht hier die Möglichkeit, sie entweder genau
wie den Zustandsvektor per Hardware (d.h. per Ablaufsteuerung) zu retten oder
per Maschinenbefehl(e), also programmgesteuert.
Während bei der Hardware-Lösung sämtliche Register gerettet werden
müssen (sie "weiß" je nicht, welche es sein müssen), kann
die programmierte Lösung sich auf genau die Register beschränken, die
in der ISR verändert werden (der Programmierer weiß welche - hoffentlich!).
Die sicherere und meist auch schnellere, jedoch auch aufwendigere Methode ist
die Hardware-Lösung.
Die Notwendigkeit, bei der Ausführung einer Programmunterbrechung zunächst
den Zustand des unterbrochenen Programms zu retten, kann also eine Reihe von Transportoperationen
benötigen; vom Moment des Eintreffens der Unterbrechnungsanforderung vergeht
daher einige Zeit, die Interrupt-Reaktionszeit, bis der erste produktive Befehl
der ISR ausgeführt wird. Diese Reaktionszeit setzt sich aus den folgenden
Komponenten zusammen:
- T1: Durchschaltezeit (der Anforderung bis zur Unterbrechungsanmeldung) aufgrund
einer gesetzten Sperre (z.B. auch dann, wenn gerade eine Interrupt-Service-Routine
bearbeitet wird). Diese Zeit kann u.U. recht lang sein!
- T2: Wartezeit bis zur Beendigung des gerade ausgeführten Befehls (maximal
die des längsten vorkommenden Befehls)
- T3: Zeit zum Retten des Programm-Zustandes und Laden des Unterbrechungs-Vektors.
Selbst wenn die Durchschaltung der Anforderung unmittelbar erfolgt (T1 = 0, weil
keine Sperre gesetzt ist), kann die Summe von T2 und T3 für zeitkritische
Echtzeitanforderungen doch noch zu groß sein.
|
|
|
